
Unifying Data Lake Architectures with Apache Iceberg and Amazon Managed Service for Apache Flink to Eliminate Dual-Pipeline Inefficiencies

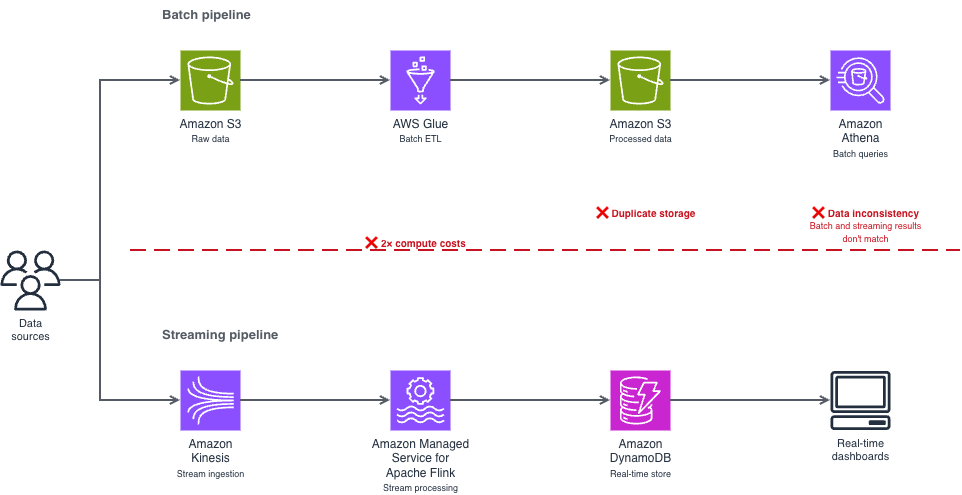
The landscape of modern data engineering is currently undergoing a significant shift as enterprises move away from the traditional, fragmented approach to data processing. For years, organizations have relied on the "dual-pipeline" architecture—maintaining one pipeline for real-time streaming and another for batch processing—to handle the varying latencies required for business intelligence and operational analytics. However, this model has introduced substantial technical debt, high operational costs, and frequent data synchronization issues. AWS has recently highlighted a more streamlined alternative: a unified pipeline architecture utilizing Apache Iceberg and Amazon Managed Service for Apache Flink. This approach allows teams to process real-time data directly from their data lakes without the overhead of redundant infrastructure, marking a pivotal moment in the evolution of cloud-native data strategies.
The Historical Context: The Rise and Fall of the Dual-Pipeline Model
To understand the significance of this unified approach, one must examine the history of data processing architectures. In the early 2010s, the "Lambda Architecture" became the industry standard. It was designed to handle massive quantities of data by providing a "speed layer" for low-latency results and a "batch layer" for comprehensive, accurate historical views. While revolutionary at the time, the Lambda Architecture required developers to maintain two separate codebases and two different sets of infrastructure.
By the mid-2020s, the limitations of this model became a primary pain point for Chief Technology Officers. The dual-pipeline approach creates three fundamental problems: excessive infrastructure costs, as companies pay for duplicate compute and storage; operational complexity, requiring engineers to manage two different monitoring and alerting systems; and data inconsistency, where the "real-time" view often drifts from the "batch" view due to different processing logic. The introduction of open-source table formats like Apache Iceberg has finally provided the technological foundation necessary to collapse these two paths into a single, cohesive stream.
The Technical Foundations of the Unified Architecture
The cornerstone of this new architectural pattern is the Apache Iceberg table format. Iceberg is an open table format for huge analytic datasets, designed to bring the reliability and simplicity of SQL tables to big data. Unlike traditional Hive-based data lakes, Iceberg uses a snapshot-based architecture.
In this unified model, snapshots function similarly to commits in a version control system like Git. Every time data is written to an Iceberg table, a new snapshot is generated. This snapshot points to the new data files while maintaining references to the existing ones. Amazon Managed Service for Apache Flink leverages these snapshots to perform incremental reads. Instead of scanning an entire S3 bucket, the Flink application identifies only the changes between snapshots—specifically the new files that have arrived since the last checkpoint.
This mechanism ensures Atomicity, Consistency, Isolation, and Durability (ACID). In a practical business scenario, such as a retail giant processing 10,000 transaction records, ACID transactions ensure that a streaming query sees either the entire set of records or none at all. This prevents the "partial data" problem that historically plagued real-time analytics and led to skewed financial reporting.
Core Components of the AWS Integration
The implementation of a unified pipeline involves four primary AWS services and a suite of open-source libraries. The workflow begins with data landing in Amazon Simple Storage Service (S3) formatted as Apache Iceberg files. The metadata and schema for these files are managed by the AWS Glue Data Catalog, which acts as the central repository for table definitions.

Amazon Managed Service for Apache Flink serves as the processing engine. It is configured to monitor the Iceberg snapshots at a specified interval. The technical complexity of this integration is managed through several critical Java Archive (JAR) dependencies, including the flink-s3-fs-hadoop connector and the iceberg-flink-runtime. These libraries allow Flink to communicate across different layers of the stack—coordinating between S3 for storage, Glue for metadata, and Hadoop for file-level operations.
Industry experts note that the choice of monitor-interval is a critical economic and performance lever. A three-second interval provides near-instantaneous data availability but can generate upwards of 1,200 Amazon S3 LIST API calls per hour. At current pricing models, this equates to roughly $0.04 per month per table. While this seems negligible for a single table, at an enterprise scale with thousands of tables, these costs must be managed by adjusting intervals based on the specific time-sensitivity of the workload.
Economic Analysis and Cost Management
One of the primary drivers for adopting a unified pipeline is the reduction in Total Cost of Ownership (TCO). Traditional streaming architectures often involve high fixed costs for "always-on" clusters. In contrast, the AWS-managed Flink environment charges based on Kinesis Processing Units (KPUs), with a standard rate of approximately $0.11 per hour per KPU.
By consolidating into a single pipeline, organizations can reduce their compute footprint by an estimated 30% to 50%. Furthermore, the use of Amazon S3 Intelligent-Tiering for the underlying Iceberg data files can optimize storage costs. Since data in a unified pipeline typically follows a predictable access pattern—frequent access for recent snapshots and rare access for historical data—Intelligent-Tiering automatically moves older data to lower-cost tiers, potentially saving another 20% on storage overhead.
However, batch processing still holds an economic advantage for certain use cases. If a dataset only needs to be processed once a day or if the queries are primarily focused on long-term historical trends, the continuous runtime of a Flink application may be less cost-effective than a scheduled AWS Glue ETL job. The industry consensus is that the unified streaming pattern is most effective for scenarios requiring data availability within seconds to minutes, such as fraud detection, real-time inventory management, or dynamic pricing engines.
Security Protocols and Shared Responsibility
As with all cloud architectures, security remains a shared responsibility. AWS manages the security of the underlying infrastructure, while the user is responsible for securing the data and access paths. In a unified Iceberg pipeline, this involves a multi-layered security strategy.
First, Identity and Access Management (IAM) roles must be scoped to the principle of least privilege. This means the Flink application should only have s3:GetObject and s3:PutObject permissions for the specific data lake bucket and glue:GetTable permissions for the relevant database.
Second, encryption is mandatory for enterprise-grade deployments. Server-side encryption with AWS Key Management Service (SSE-KMS) ensures that data at rest is protected, while enforced TLS (Transport Layer Security) via S3 bucket policies ensures data in transit cannot be intercepted.
Finally, the use of Amazon Virtual Private Cloud (VPC) endpoints allows the Flink cluster to communicate with S3 and Glue over the private AWS network, bypassing the public internet entirely. This significantly reduces the attack surface and is a requirement for most compliance frameworks, such as SOC2 or HIPAA.
Operational Excellence and Performance Tuning
Transitioning to a production-ready unified pipeline requires meticulous performance tuning. Partition pruning is the most effective way to optimize query performance in an Iceberg-based system. By partitioning data by date or region, the Flink application can skip entire directories of irrelevant data, drastically reducing I/O overhead.
Checkpointing is another vital operational component. In Apache Flink, checkpointing provides "exactly-once" processing semantics, ensuring that even if a system failure occurs, no data is lost or duplicated. For moderate volumes—up to 10,000 records per second—a 10-second to 30-second checkpoint interval is generally recommended. If the checkpoint duration begins to exceed 50% of the interval, it serves as a leading indicator that the system is under-provisioned and requires additional KPUs or increased parallelism.
The Broader Impact on Enterprise Data Strategy
The move toward a unified pipeline architecture represents more than just a technical upgrade; it is a fundamental shift in how businesses interact with their data. By removing the lag between data ingestion and availability, companies can move from reactive to proactive decision-making.
In the retail sector, this allows for "just-in-time" inventory updates that prevent stockouts during peak shopping periods. In financial services, it enables more sophisticated fraud detection models that can analyze transaction patterns against historical data in a single, unified stream.
Furthermore, the adoption of open-source formats like Apache Iceberg prevents "vendor lock-in." Because the data is stored in an open format on S3, organizations retain the flexibility to use different processing engines in the future, whether they be Amazon Athena for ad-hoc SQL queries or Amazon EMR for heavy-duty machine learning workloads.
Conclusion and Future Outlook
The convergence of streaming and batch processing into a single, Iceberg-backed pipeline on AWS marks the end of the dual-pipeline era. By eliminating the redundancy of the Lambda Architecture, enterprises can achieve higher data consistency, lower operational costs, and faster time-to-insight. As Amazon Managed Service for Apache Flink continues to evolve, we can expect further integrations that simplify the deployment of these complex systems.
For data engineering teams, the path forward involves a transition from managing infrastructure to managing data logic. The technical barriers that once necessitated separate pipelines have been dismantled by the snapshot capabilities of Iceberg and the managed scalability of AWS. The result is a more agile, cost-effective, and reliable data ecosystem that is better equipped to handle the demands of the modern digital economy. Organizations that embrace this unified approach today will likely find themselves at a significant competitive advantage as the volume and velocity of global data continue to accelerate.

{kind=link}